Local-first · Claude Code + Codex · open source
One dashboard for every AI coding agent.
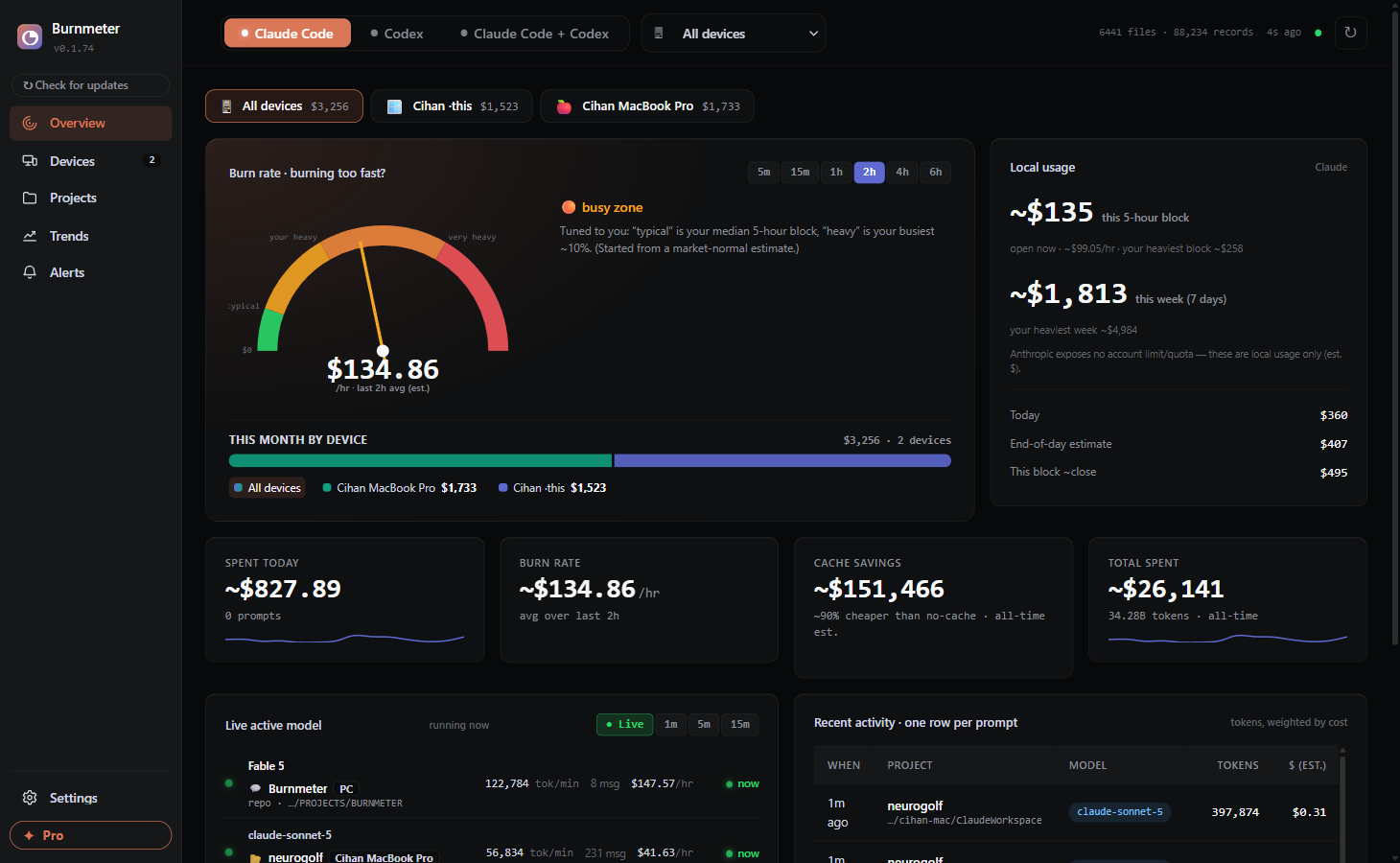
See exactly where your tokens go — cost, burn-rate, and how close you are to your plan's rate limit. No API keys. No cloud. Your data never leaves your machine.
Free · no Python needed · native app + system tray · your data never leaves your machine
Unsigned for now — if Windows SmartScreen appears, click More info → Run anyway.
Unsigned for now — if Windows SmartScreen appears, click More info → Run anyway.
macOS & Linux
Native window · no security prompt · needs Python 3.10+
pip install --upgrade "burnmeter[app] @ git+https://github.com/cihanatak/BurnMeter"
burnmeter
AGPL-3.0 open source
Local-first · no cloud
No API keys
Claude Code + Codex
Python 3.10+
Dashboard preview · the maker's real usage (v0.1.74)